CoST:Contrastive-Learning-of-Disentangled-Seasonal-Trend-Representations-for-Time-Series-Forecasting
来自ICLR 2022 (oral) 的 工作 CoST: Contrastive Learning of Disentangled Seasonal-Trend Representations for Time Series Forecasting
论文研究的主要背景
现在有很多的是时序预测工作,受到CV&NLP方面的影响,作者希望提出一个 pretrain + fine-tune 的预测框架
而时序数据具体受 season 和 trend等因素影响
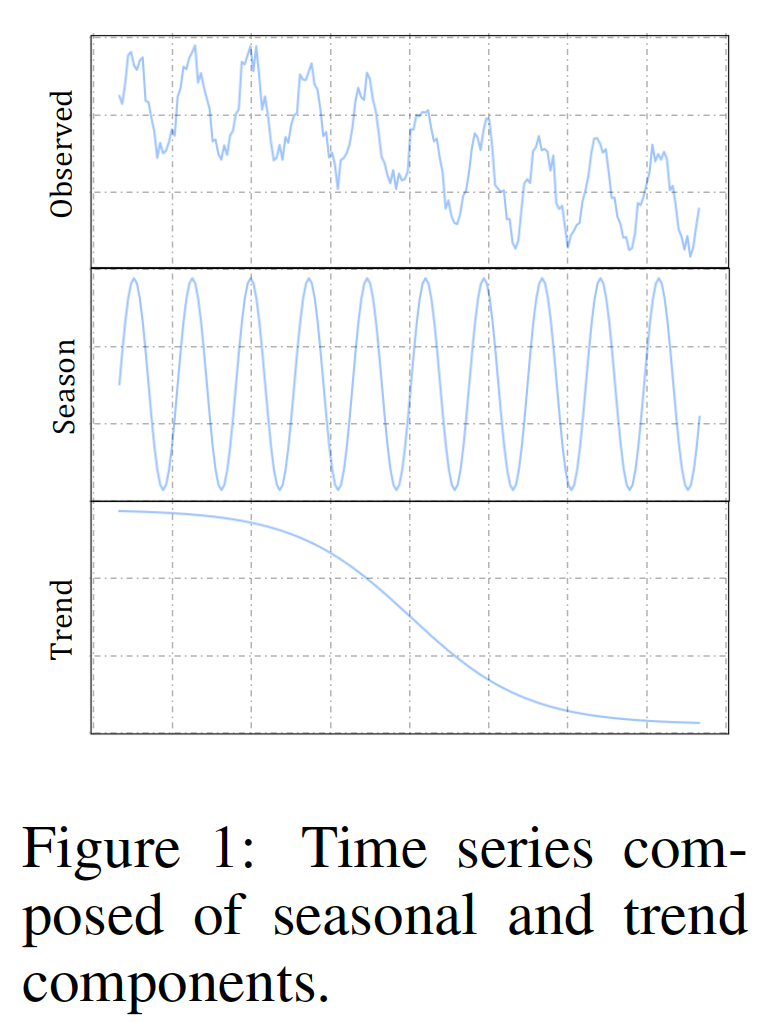
因此作者应用 contrastive learning 来分别学习 discriminative trend 和 seasonal representations
论文试图解决什么问题
直接的端到端的预测模型可能会导致模型过拟合和受到观测数据中包含的不可预测噪声的影响。因此作者应用 contrastive learning 来分别学习 discriminative trend 和 seasonal representations。同时整体应用 pre-train + fine-tune的框架
贡献
- 通过因果关系的观点,我们证明了通过对比学习来解开时间序列预测的季节性趋势表示的好处。
2。我们提出了CoST,这是一种时间序列表示学习方法,它利用模型结构中的归纳偏差来学习分解的季节和趋势表示,以及结合一种新的频域对比损耗来鼓励有区别的季节表示。
3。成本比现有的最先进的方法在现实世界的
基准上有相当大的优势-多元设置的MSE提高了21.3%。我们还分析了每个提出的模块的优点,并通过广泛的消融研究确定CoST对于各种选择的骨干编码器和下游回归器是鲁棒的。
科学假设
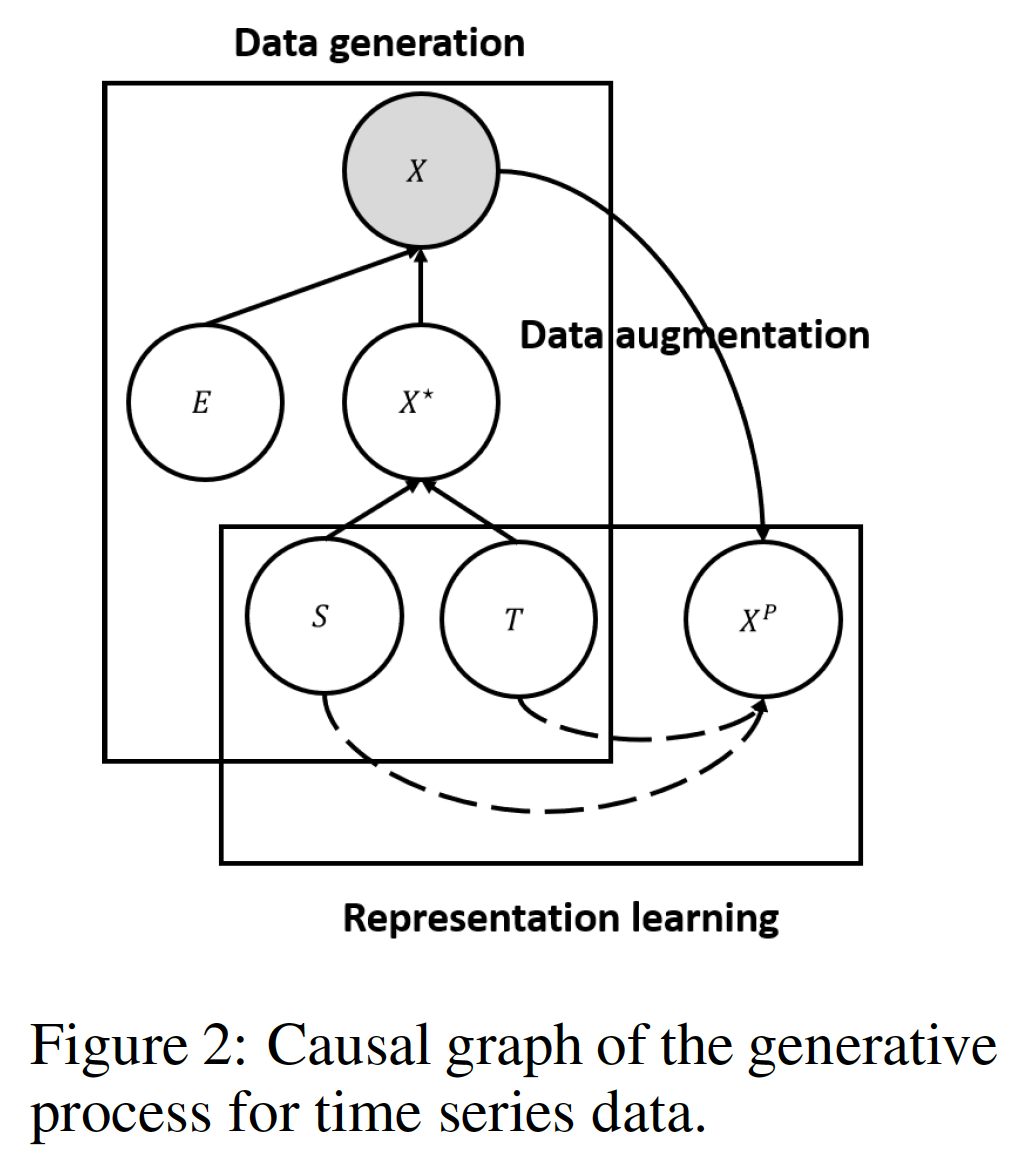
观测值 X 受到 error variable E 和 error-free latent variable X* 的影响,
其中 X* 受 trend variable T 和 seasonal variable S的影响
而 E 是无法预估的,因此作者通过考虑 S 和 T 来学习 X*
其次, S 和 T是相互独立的 (虽然有引用,但是没具体阐释)
但是由于 X* 是无法得到的,因此作者构建了一个 proxy contrastive learning task。具体来说,通过data argumentation的方式来模拟E的影响,同时通过 contrastive learning 分别学习 S & T。由于E难以全面的生成,因此这里只去考虑了三种典型的data argumentation方式: scale, shift, and jitter.
论文中提到的解决方案之关键是什么
整体框架
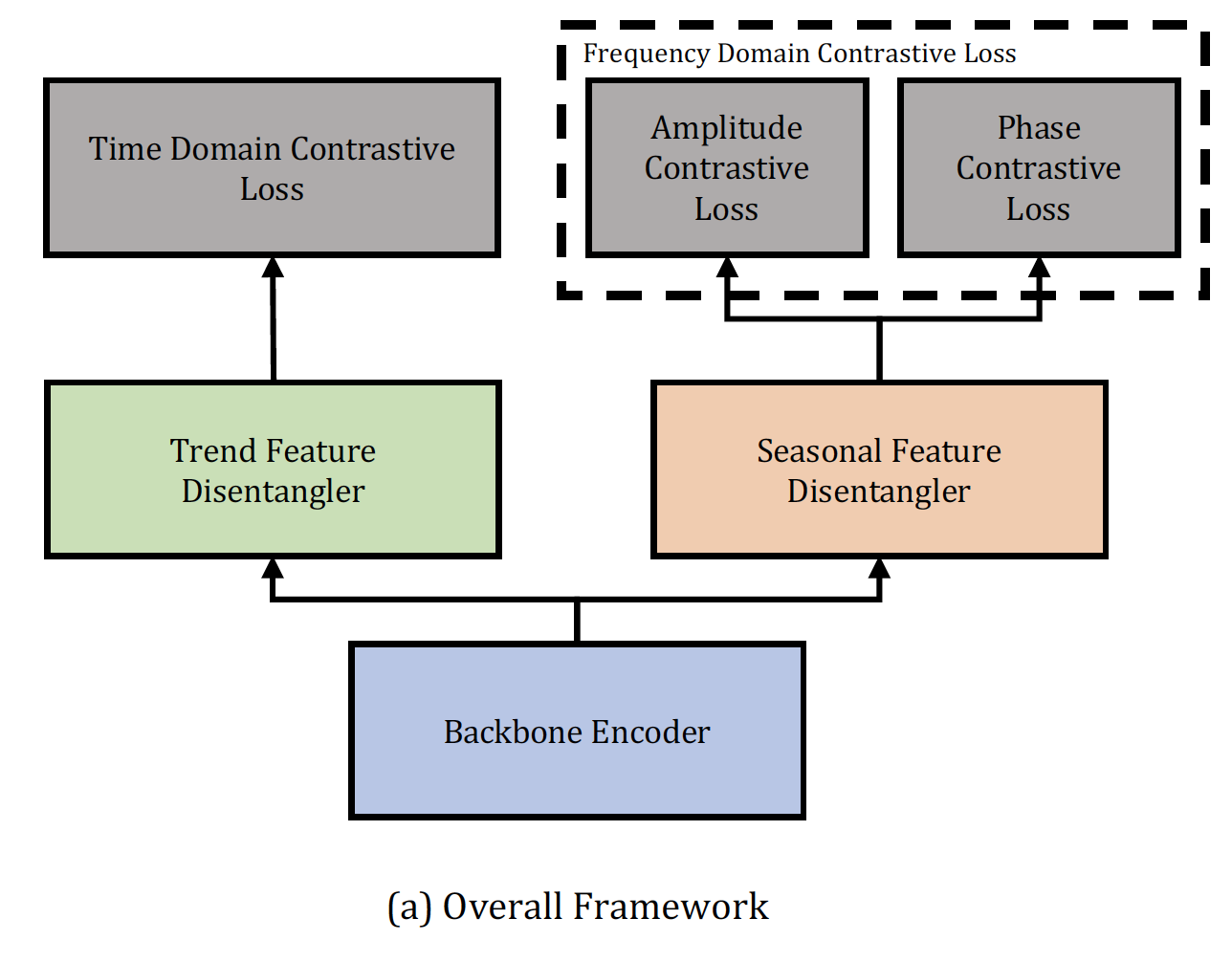
Backbone encoder : $\mathbb{R}^{h \times m} \rightarrow \mathbb{R}^{h \times d}$
Trend Feature Disentangler (TFD), $f_{T}: \mathbb{R}^{h \times d} \rightarrow \mathbb{R}^{h \times d_{T}}$
Seasonal Feature Disentangler (SFD), $f_{S}: \mathbb{R}^{h \times d} \rightarrow \mathbb{R}^{h \times d_{S}}$
Loss $\mathcal{L}=\mathcal{L}_{\text {time }}+\frac{\alpha}{2}\left(\mathcal{L}_{\mathrm{amp}}+\mathcal{L}_{\text {phase }}\right)$
TFR
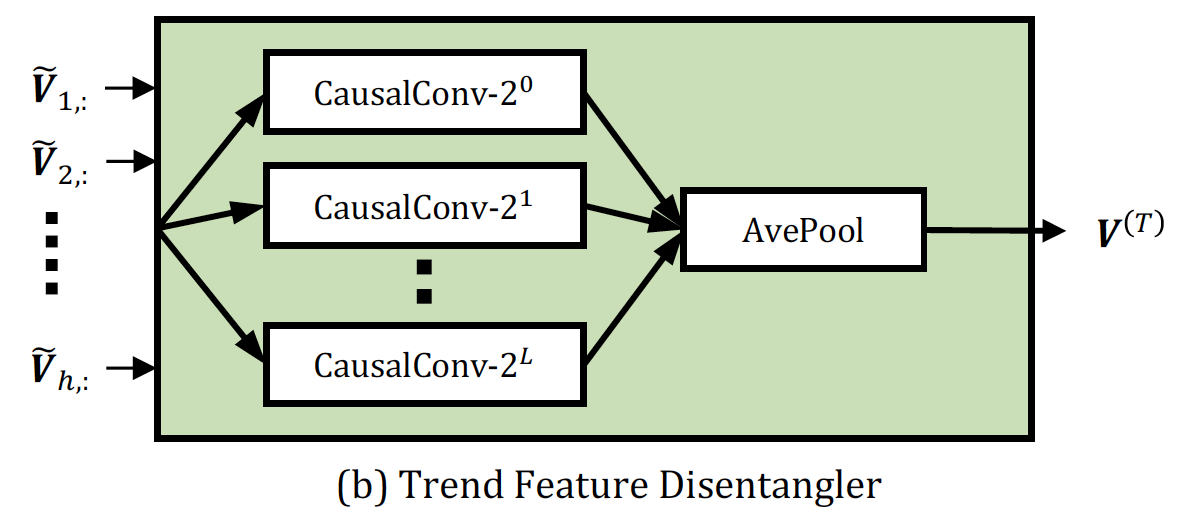
在时序输入上,通过多个kernel size不同的卷积核,再做average
Loss针对contrastive learning进行设置
$\mathcal{L}_{\text {time }}=\sum_{i=1}^{N}-\log \frac{\exp \left(\boldsymbol{q}_{i} \cdot \boldsymbol{k}_{i} / \tau\right)}{\exp \left(\boldsymbol{q}_{i} \cdot \boldsymbol{k}_{i} / \tau\right)+\sum_{j=1}^{K} \exp \left(\boldsymbol{q}_{i} \cdot \boldsymbol{k}_{j} / \tau\right)}$
我们首先选择一个随机的时间步长t作为对比损失,并应用一个投影头,它是一个单层的MLP来获得q, k分别是对应样本从动量编码器/动态字典中得到的增大版。
SFR
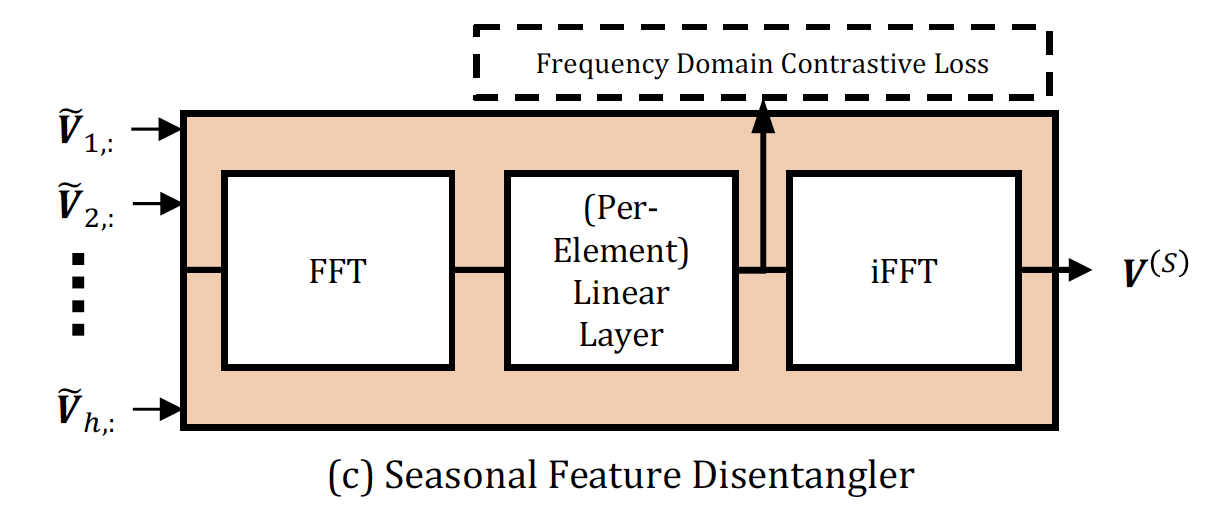
对时序上的不同输入首先通过 discrete Fourier transform 将特征 map 到 frequency domain
⇒ $\mathcal{F}(\tilde{\boldsymbol{V}}) \in \mathbb{C}^{F \times d}$ , $F=\lfloor h / 2\rfloor+1$
然后是一个线性层,再通过 inverse DFT operation 得到最终输出
其中线性层针对每个元素,
$V_{i, k}^{(S)}=\mathcal{F}^{-1}\left(\sum_{j=1}^{d} A_{i, j, k} \mathcal{F}(\tilde{\boldsymbol{V}})_{i, j}+B_{i, k}\right)$其中
$\mathbf{A} \in \mathbb{C}^{F \times d \times d_{S}}, \boldsymbol{B} \in \mathbb{C}^{F \times d_{S}}$ 为learnable parameters
Loss :
$\begin{array}{c}\mathcal{L}_{\text {amp }}=\frac{1}{F N} \sum_{i=0}^{F} \sum_{j=1}^{N}-\log \frac{\exp \left(\left|\boldsymbol{F}_{i,:}^{(j)}\right| \cdot\left|\left(\boldsymbol{F}_{i,:}^{(j)}\right)^{\prime}\right|\right)}{\exp \left(\left|\boldsymbol{F}_{i,:}^{(j)}\right| \cdot\left|\left(\boldsymbol{F}_{i,:}^{(j)}\right)^{\prime}\right|\right)+\sum_{k \neq j}^{N} \exp \left(\left|\boldsymbol{F}_{i,:}^{(j)}\right| \cdot\left|\boldsymbol{F}_{i,:}^{(k)}\right|\right)}, \\\mathcal{L}_{\text {phase }}=\frac{1}{F N} \sum_{i=0}^{F} \sum_{j=1}^{N}-\log \frac{\exp \left(\phi\left(\boldsymbol{F}_{i,:}^{(j)}\right) \cdot \phi\left(\left(\boldsymbol{F}_{i,:}^{(j)}\right)^{\prime}\right)\right)}{\exp \left(\phi\left(\boldsymbol{F}_{i,:}^{(j)}\right) \cdot \phi\left(\left(\boldsymbol{F}_{i,:}^{(j)}\right)^{\prime}\right)\right)+\sum_{k \neq j}^{N} \exp \left(\phi\left(\boldsymbol{F}_{i,:}^{(j)}\right) \cdot \phi\left(\boldsymbol{F}_{i,:}^{(k)}\right)\right)},\end{array}$
论文中的实验是如何设计的?
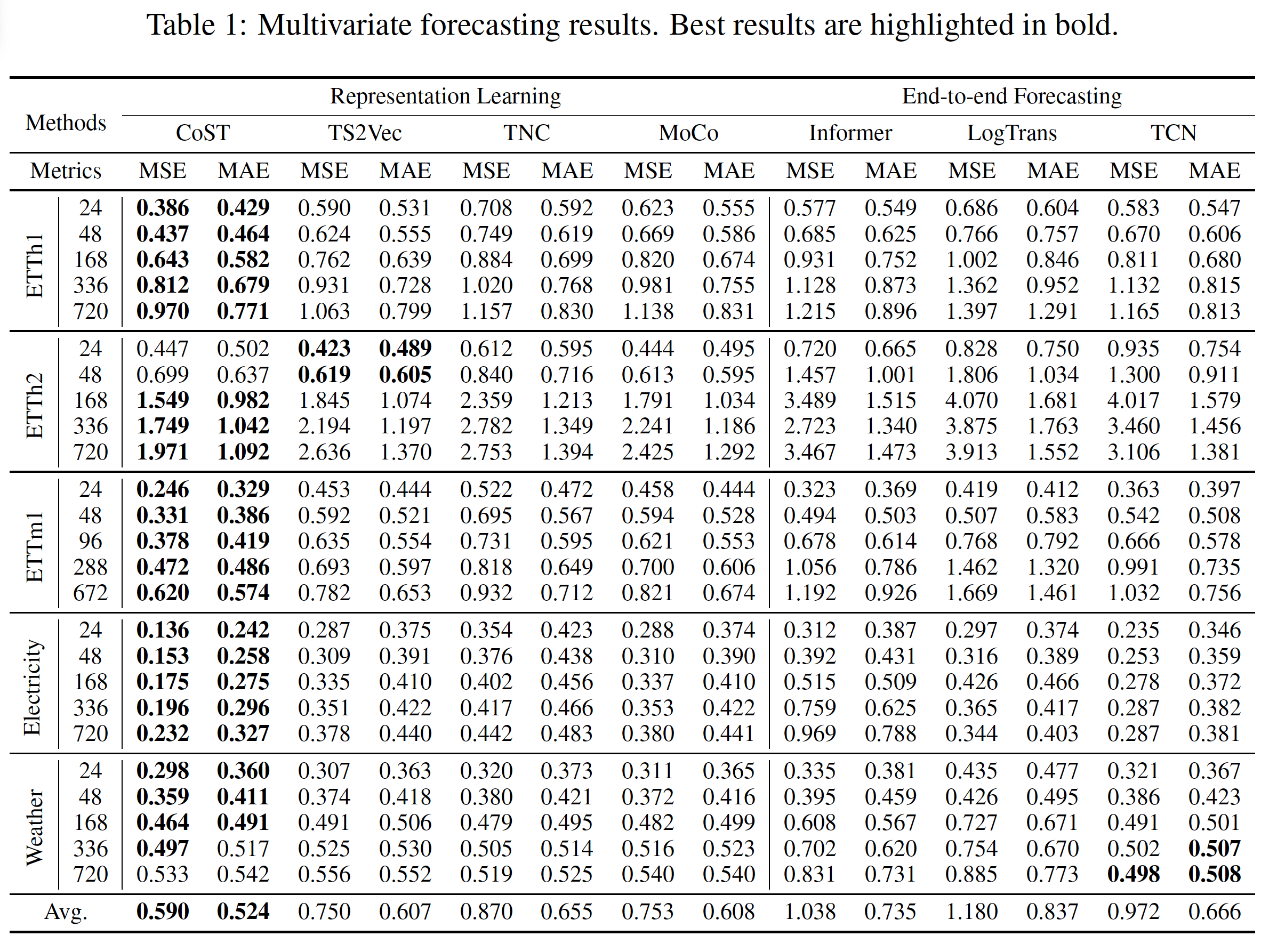
准要进行了准确性的测试,结果在部分数据集上取得了较大的提升
ablation test
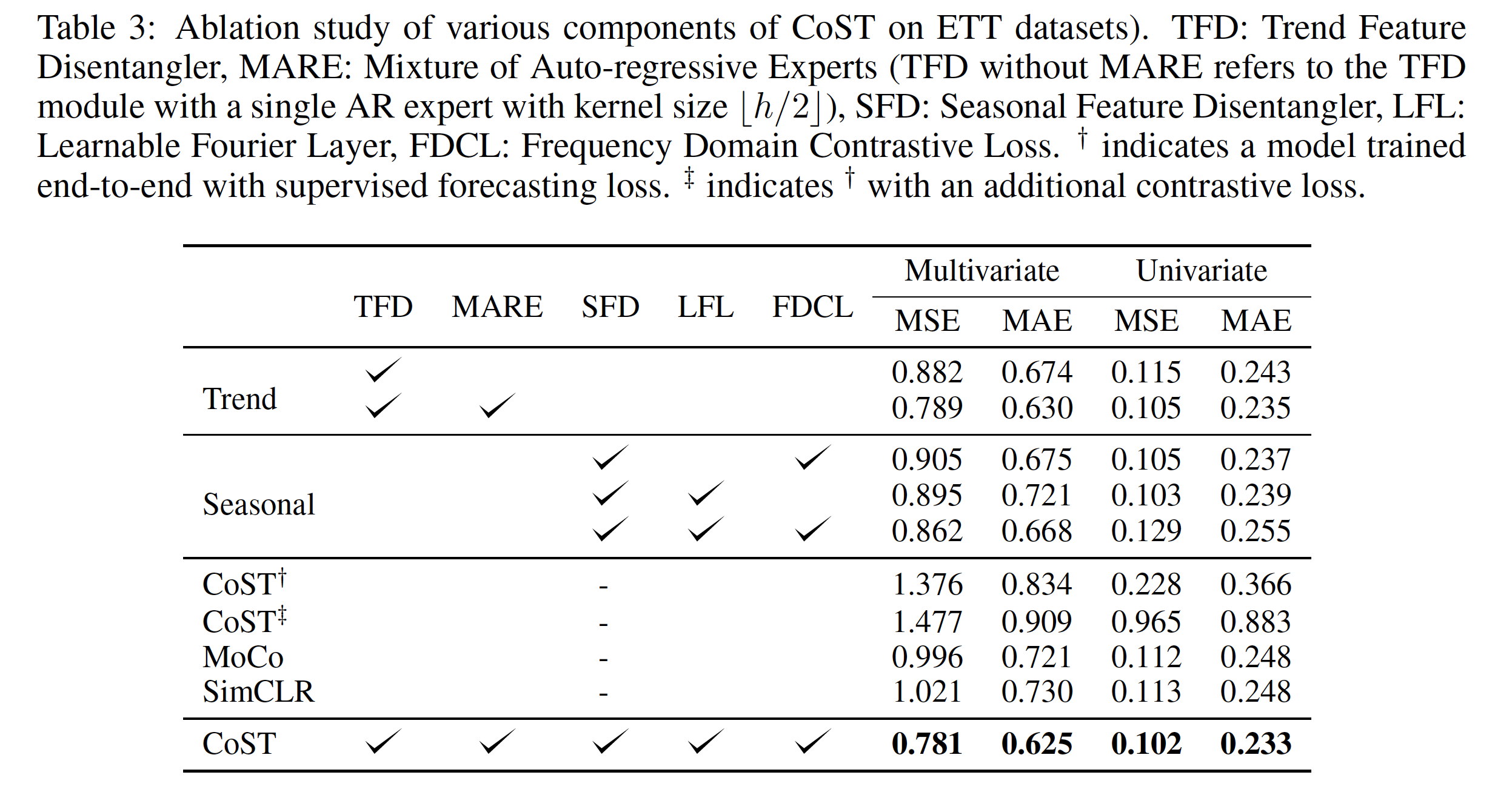
从CoST和CoST with supervised forecasting loss 结果差异可以看出 contrastive loss作用很大
这篇论文到底有什么贡献?
我们的工作表明,对于时间序列预测,将表示学习和下游预测任务分离比标准的端到端监督训练方法更有前途。我们以经验来说明这一点,并通过因果关系的观点来解释它。根据这一原则,我们提出了CoST,一种对比学习框架,用于学习时间序列预测任务的解纠缠的季节趋势表示。广泛的实证分析表明,成本比以前的最先进的方法有相当大的优势,并且对各种骨干编码器和回归器的选择是稳健的。未来的工作将把我们的框架扩展到其他时间序列情报任务。
下一步呢?有什么工作可以继续深入
针对处理时序数据提出了一个很好的想法,对trend 和 season分别进行处理,同时contrastive learning的应用让不同模块看起来更加合理,但是代码质量很差,一大遗憾。
回顾交通领域,交通数据实际上也是时序数据集中,且更加周期性,
我们也可以从这个角度出发,针对不同天内的交通数据存在 day/week pattern和 trend,然后应用contrastive learning loss设计一个模型。
CoST:Contrastive-Learning-of-Disentangled-Seasonal-Trend-Representations-for-Time-Series-Forecasting

