Informer-Beyond-Efficient-Transformer-for-Long-Sequence-Time-Series-Forecasting
Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting, AAAI’21 Best Paper
改进注意力机制来降低时间复杂度和内存消耗
在长序列上效果更佳
生成结构的 encoder,令速度更快
background
vanilla transformer 具有三个主要缺陷
- 计算开销大,对于每一个 self-attention mechanism,或者说 dot-product(维度为L),时间和内存复杂度都为O(L^2)
- 内存瓶颈,当堆叠结构具有 J 层,会导致其内存消耗为 O(J * L ^ 2)
- 输出结构,既 decoder的step-by-step的推理输出像RNN 一样缓慢
先有一些方法有部份能够解决problem 1,但是或多或少具有缺陷,同时针对problem 2 & 3 还没有很好的解决方案
Contributions
简单归纳:
提出的informer能够更好的在 LSTF 适用,针对上述三个problem具有一个的缓解
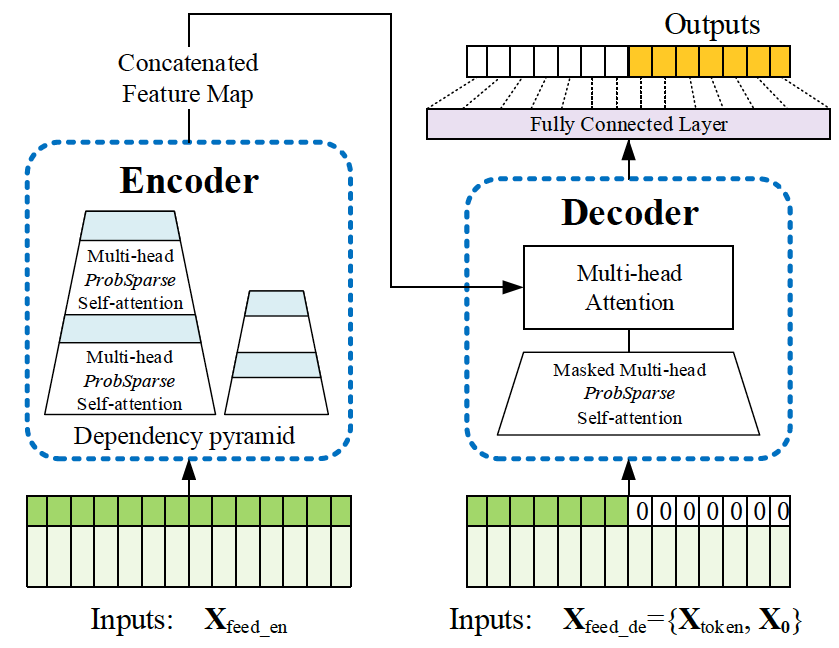
method

Efficient Self-attention Mechanism
不同于 vanilla self-attention 计算所有的ket-value pair,在此提出spare版本,只去计算比较重要的 part
如何去评判哪个比较重要,或者说如何去评判计算哪些 values
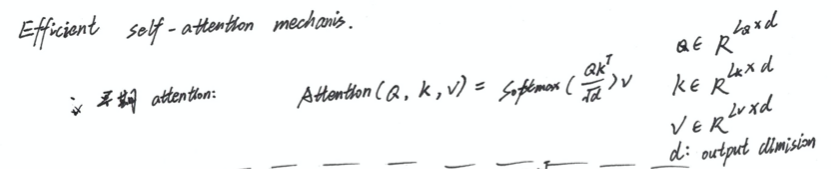
将第i对的query’s attention定义为概率,通过式 1可以得知 该概率更加偏离统一分布 q,因为如果一致,就会和residual block 冗余。

因此可以通过对 概率 p和 q的相似度来判别 i-th query’s attention的重要性
通过 KL-divergency 来进行判断
Encoder & Decoder
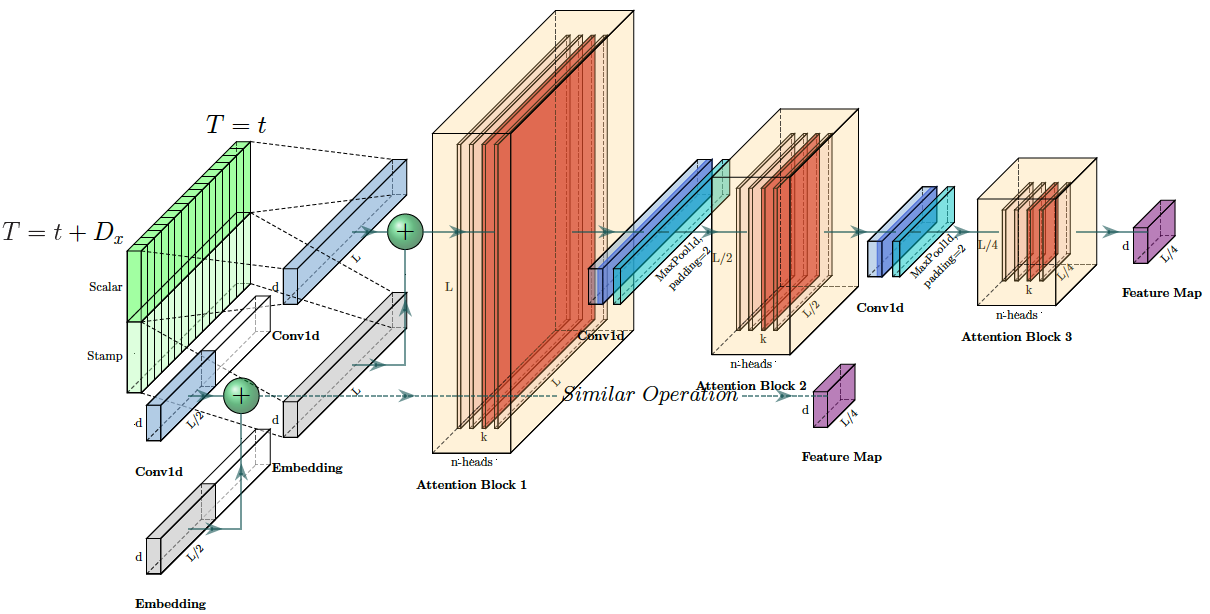
Encoder 主要被用于提取输入中的鲁棒性特征,通过 input representation,输入被reshape了一下

Experiement
在电力 & 天气 数据集上进行了验证
只是时序数据,也许之后可以用得到
Idea
主要针对Transformer的几大不足进行了优化
亮点:
- 贡献可圈可点,虽然没有那种惊艳的感觉,但是让人能看出很下功夫
- 行文/整体 思路可以借鉴,基于某个很不错的模型,在某种问题的不适用性,对模型进行优化
不足:
- 感觉没大的缺点
Informer-Beyond-Efficient-Transformer-for-Long-Sequence-Time-Series-Forecasting

